深度学习入门 -- 权重初始值的优化
深度学习入门 – 权重初始值的优化
在神经网络的学习中,权重的初始值特别重要,它经常关系到神经网络的学习能否成功。
权重初始值的优化有三个要点(结论):
- 权重初始值必须是随机生成的。
- 当激活函数使用
sigmoid或tanh函数(正切函数)等 S 型曲线函数时,初始值使用Xavier初始值。 - 当激活函数使用
ReLU时,权重初始值使用He初始值。
随机生成的权重初始值就像这样:
1 | |
为什么要随机生成权重初始值呢?因为只有这样,才能发挥多层神经网络的学习效果。
各层的激活值的分布都要求有适当的广度(分布均匀),因为在各层之间传递多样性的数据,神经网络就可以进行高效地学习。反过来,如果传递的都是有所偏向的数据(分布不均匀),就会出现梯度消失或者 “表现力受限” 的问题,导致学习可能无法顺利进行。
接下来看看各种初始值以及对应的激活函数的激活值的不同分布,
权重初始值为标准差是 1 的高斯分布,激活函数为 sigmoid
 )
)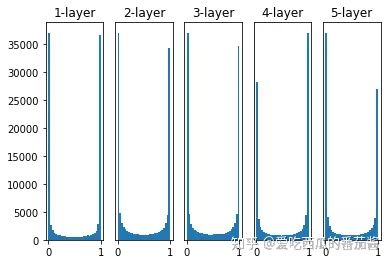
如上图,各层激活值呈偏向 0 和 1 的分布,会出现梯度消失的问题
权重初始值为标准差是 0.01 的高斯分布,激活函数为 sigmoid
 )
)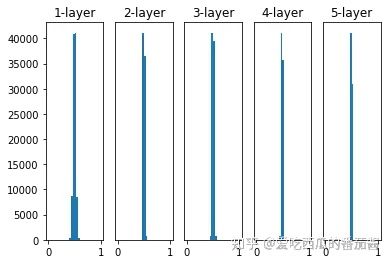
这次的激活值集中在 0.5 附近,会出现表现力受限的问题。
权重初始值为 Xavier 初始值,激活函数为 sigmoid
Xavier初始值即是标准差为sqrt(1/n)的高斯分布:
1 | |
效果如下:
 )
)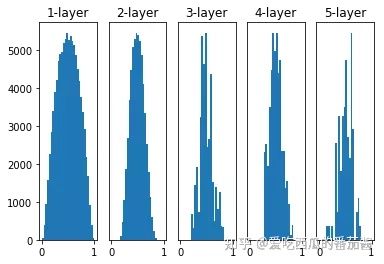
可以看出,各层激活值的分布更有广度,所以 sigmoid 函数的表现力不受限制,有望进行高效地学习。
权重初始值为 He 初始值,激活函数为 sigmoid
He初始值即是标准差为sqrt(2/n)的高斯分布:
1 | |
效果如下:
 )
)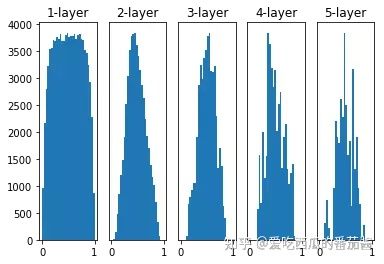
可以看出,当激活函数为sigmoid时,He初始值的效果仍然不错。
激活函数使用 ReLU 时,不同权重初始值的激活值分布的变化
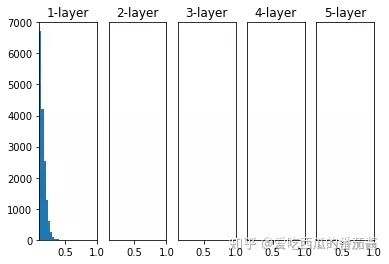
权重初始值为标准差是 0.01 的高斯分布时:
 )
)
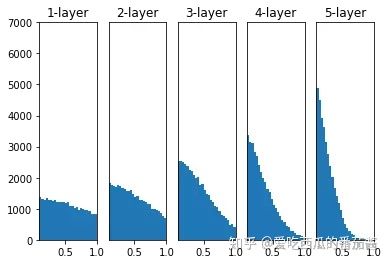
权重初始值为 Xavier 初始值时:
 )
)
**
权重初始值为 He 初始值时:**
 )
)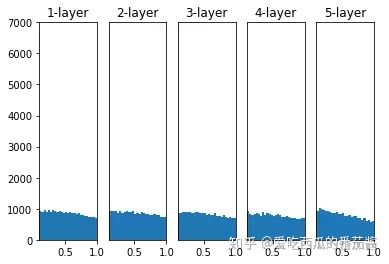
总结,当激活函数使用 ReLU, 权重初始值使用He初始值;当激活函数使用 sigmoid 时,权重初始值使用Xavier初始值。
基于 MNIST 数据集的权重初始值的比较:
这里以标准差为0.01的高斯分布 、Xavier初始值、He初始值三种初始值进行实验。
并且由上一篇文章的知识可知,权重偏置等参数的更新有四种方式:
- SGD
- Momentum
- AdaGrad
- Adam
用 SGD 更新参数的条件下,基于 MNIST 数据集的三种权重初始值的比较如下图:
 )
)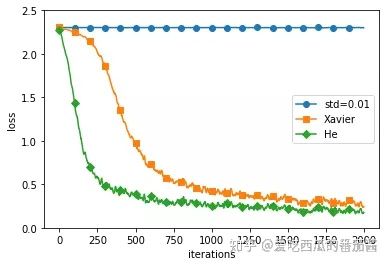
如上图,std=0.01时,完全无法进行学习,当权重初始值为He初始值时,学习效果最好,进度最快。
用 Adam 更新参数的条件下,基于 MNIST 数据集的三种权重初始值的比较如下图:
 )
)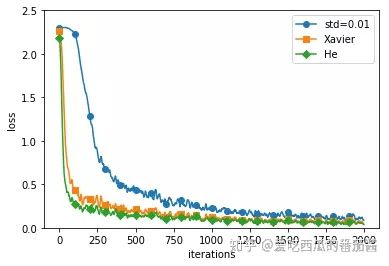
如上图,三种权重初始值都能得到较好的学习效果,其中仍然是权重初始值为He初始值的学习效果最佳。说明一个好的更新参数的方法带来的优势可以抵消不良的权重初始值带来的劣势。
用一句话总结今天的文章:如果不知道使用什么权重初始值,那就使用
He初始值;Adam方法带来的影响大于初始值带来的影响。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!