优化( optimization)和泛化 (generalization)——减少过拟合和欠拟合
优化( optimization)和泛化 (generalization)——减少过拟合和欠拟合
基本原则
机器学习的根本问题是优化和泛化之间的对立。
优化( optimization)是指调节模型以在训练数据上得到最佳性能(即机器学习中的学习)
而泛化( generalization)是指训练好的模型在前所未见的数据上的性能好坏。
机器学习的目的当然是得到良好的泛化,但你无法控制泛化,只能基于训练数据调节模型。
基本思路
- 增大训练数据量
- 调节模型存储信息量
- 对存储信息加以约束,使模型集中学习重要的模式——正则化( regularization)
调整储存信息量(记忆容量memorization capacity)
在深度学习中,模型中可学习参数的个数通常被称为模型的容量( capacity)。
直观上来看,参数更多的模型拥有更大的记忆容量( memorization capacity),因此能够在训练样本和目标之间轻松地学会完美的字典式映射,但这种映射没有任何泛化能力。
但是 如果数据量过大, 模型无法学会这种映射,则需要学会他的*压缩表示 *,及减少输入的“个数”
但没有一个魔法公式能够确定最佳层数或每层的最佳大小。你必须评估一系列不
同的网络架构(当然是在验证集上评估,而不是在测试集上),以便为数据找到最佳的模型大小。
要找到合适的模型大小,一般的工作流程是开始时选择相对较少的层和参数,然后逐渐增加层
**
**的大小或增加新层,直到这种增加对验证损失的影响变得很小。
添加权重正则化(weight regularization)
强制让模型权重只能取较小的值,从而限制模型的复杂度,这使得权重值的分布更加规则( regular)
**
- L1 正则化( L1 regularization):添加的成本与权重系数的绝对值[权重的 L1 范数( norm)]
成正比。 - L2 正则化( L2 regularization):添加的成本与权重系数的平方(权重的 L2 范数)成正比。
神经网络的 L2 正则化也叫权重衰减( weight decay)
1 | |
kernel_regularizer=regularizers.l2(0.001) ——该层权重矩阵的每个系数都会使网络总损失增加 0.001 * weight_
coefficient_value
dropout正则化
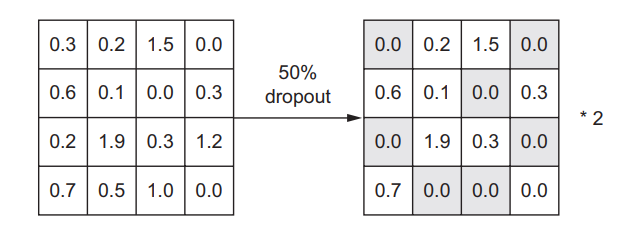
dropout 是神经网络最有效也最常用的正则化方法之一
它是由多伦多大学的 Geoffrey Hinton和他的学生开发的。对某一层使用 dropout,就是在训练过程中随机将该层的一些输出特征舍弃(设置为 0)。
假设在训练过程中,某一层对给定输入样本的返回值应该是向量 [0.2, 0.5,1.3, 0.8, 1.1]。使用 dropout 后,这个向量会有几个随机的元素变成 0,比如 [0, 0.5,1.3, 0, 1.1]。 dropout 比率( dropout rate)是被设为 0 的特征所占的比例,通常在 0.2~0.5范围内。测试时没有单元被舍弃,而该层的输出值需要按 dropout 比率缩小,因为这时比训练时有更多的单元被激活,需要加以平衡。
Hinton 说他的灵感之一来自于银行的防欺诈机制。用他自己的话来说:“我去银行办理业务。柜员不停地换人,于是我问其中一人这是为什么。他说他不知道,但他们经常换来换去。我猜想, 银行工作人员要想成
功欺诈银行,他们之间要互相合作才行。
这让我意识到,在每个样本中随机删除不同的部分神经元,可以阻止它们的阴谋,因此可以降低过拟合。”
其核心思想是在层的输出值中引入噪声,打破不显著的偶然模式( Hinton 称之为阴谋)。
1 | |
一般在每个隐层结束后都加入dropout
?
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!