神经网络——基于 relu 激活Dense 层堆叠
神经网络——基于 relu 激活Dense 层堆叠
参数 num_words=10000 的意思是仅保留训练数据中前 10 000 个最常出现的单词。低频单词将被舍弃。这样得到的向量数据不会太大,便于处理。
准备数据
解码:

/?是什么意思….
将列表转换为张量
转化为2进制矩阵,(one-hot 编码)
举个例子,序列 [3, 5] 将会
被转换为 10 000 维向量,只有索引为 3 和 5 的元素是 1,其余元素都是 0。然后网络第
一层可以用 Dense 层,它能够处理浮点数向量数据。

构建网络
输入数据是向量,而标签是标量( 1 和 0),这是你会遇到的最简单的情况。有一类网络在这种问题上表现很好,就是带有 relu 激活的全连接层( Dense)的简单堆叠,比如Dense(16, activation=’relu’)。
其中:6 个隐藏单元对应的权重矩阵 W 的形状为 (input_dimension, 16)
w.x相当于投影到 16维的向量(表示空间) 再加上b 应用RELU;
对于这种 Dense 层的堆叠,你需要确定以下两个关键架构:
- 网络有多少层;
- 每层有多少个隐藏单元。
现在暂时规定 unit = 16, layer3 为输出标量(D = 1)
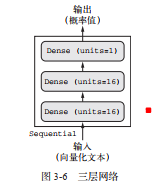
其中,第三层因为输出 概率,可以把RELU换为sigmoid激活

损失函数和优化器选择
由于你面对的是一个二分类问题,网络输出是一个概率值(网络最后一层使用 sigmoid 激活函数,仅包含一个单元),那么最好使用 binary_crossentropy(二元交叉熵)损失。这并不是唯一可行的选择,比如你还可以使用 mean_squared_error(均方误差)。但对于输出概率值的模型, 交叉熵( crossentropy)往往是最好
的选择。交叉熵是来自于信息论领域的概念,用于衡量概率分布之间的距离,在这个例子中就
是真实分布与预测值之间的距离。
下面的步骤是用 rmsprop 优化器和 binary_crossentropy 损失函数来配置模型。注意,
我们还在训练过程中监控精度。
Q:监控精度? metrics参数学习

训练模型


损失和精度检验
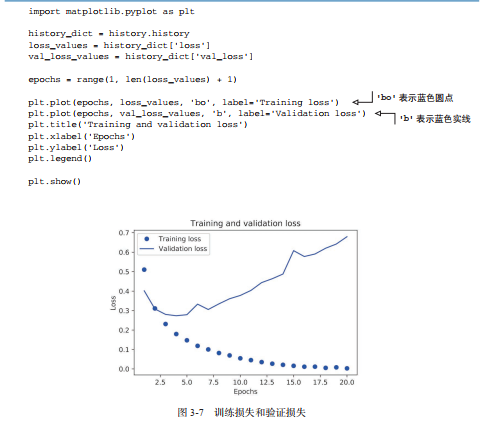

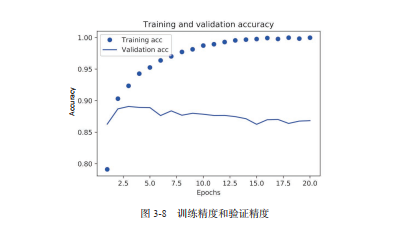
明显发现,出现过拟合现象
**
可以提前设置停止训练(减少迭代),也有其他方法(小记和后续会讲)
代码中将训练轮数改为 4,效果更好。

交叉熵理论
交叉熵与熵相对,如同协方差与方差。
熵考察的是单个的信息(分布)的期望,”信息熵” (information entropy)
是度量样本集合纯度最常用的一种指标. 假定当前样本集合 D 中第 k 类样本所占的比例为 Pk (k = 1,2,. . . , IYI),则 D 的信息熵定义为 :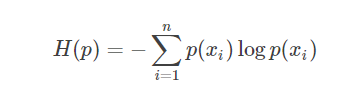
交叉熵考察的是两个的信息(分布)的期望(两个分布之间的”距离”):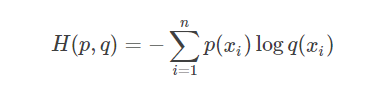
交叉熵代价函数
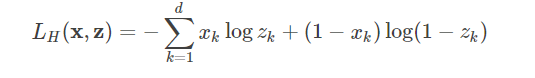
为神经网络引入交叉熵代价函数,是为了弥补 sigmoid 型函数的导数形式易发生饱和(saturate,梯度更新的较慢)的缺陷(x越大曲线越平缓)。
原因
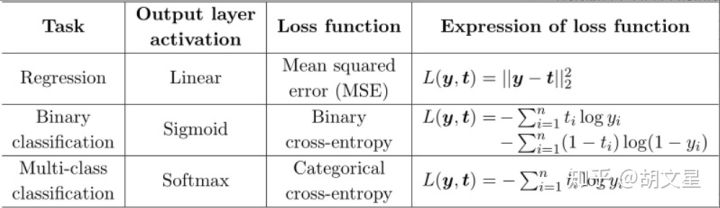
softmax在下一节会讲到
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!