LSTM -Pytorch实现&解构
部分源码和思路来源于 《Dive-into-DL-PyTorch》,很好的一本进阶书籍,推荐学习!
本文适合对pytorch.nn,python-generator有一定基础的人观看,若对DL感兴趣想入门的朋友,推荐去看李宏毅2020的网课。
LSTM介绍
LSTM 中引入了3个门,即输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及与隐藏状态形状相同的记忆细胞(某些文献把记忆细胞当成一种特殊的隐藏状态),从而记录额外的信息。
下图是一层lstm的图示,很好的展示了lstm的“记忆”过程:
本次模型目标为:
- 记忆周杰伦的歌词习惯
- 给出一个歌词集里出现过的字,输出下一个字,迭代50次生成一句歌词,同时预设歌词开头为”分开”
数据预处理
数据介绍:运用的周杰伦歌词集的text。因lyric数据具有很强的时序性,因此用lstm。同时为了突出时序,在小批量训练时我们用 *相邻采样 *而非一般的随机采样,后面会有介绍。
标注
- 读取某文本的前10000个字符,需要将字符转码为独热编码
- 独热编码前,需要对每种字符进行”编号”,这里用了python的set和enumerate来生成不重复序列对象作为字典标识char
- 用字典(char_to_idx)来对每个char标注,再以字典进行独热编码,作为训练数据
1
2
3
4
5
6
7
8
9
10
11
12
13# 设定学习所需的基本参数,后面会详细解释
vocab_size: 1027 —— 就是len(char_to_idx)
num_input & num_output:1027, num_hidden: 256 # 规定LSTM的基本参数
num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2
# 对read的字符进行处理
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[0:10000]
idx_to_char = list(set(corpus_chars))
char_to_idx = dict([(char, i) for i, char in enumerate(idx_to_char)]) # 列表解析,后面将多次用到
vocab_size = len(char_to_idx)
corpus_indices = [char_to_idx[char] for char in corpus_chars]
# one-hot步骤忽略,比较简单生成器构造
如果想要自定义每次迭代时的过程,我们需要使用生成器
生成迭代对象
相邻取样
引自D2L原文
令相邻的两个随机小批量在原始序列上的位置相毗邻。这时候,我们就可以用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态,从而使下一个小批量的输出也取决于当前小批量的输入,并如此循环下去。这对实现循环神经网络造成了两方面影响:一方面, 在训练模型时,我们只需在每一个迭代周期开始时初始化隐藏状态;另一方面,当多个相邻小批量通过传递隐藏状态串联起来时,模型参数的梯度计算将依赖所有串联起来的小批量序列。同一迭代周期中,随着迭代次数的增加,梯度的计算开销会越来越大。 为了使模型参数的梯度计算只依赖一次迭代读取的小批量序列,我们可以在每次读取小批量前将隐藏状态从计算图中分离出来。
1 | |
这里可视化一下相邻取样的逻辑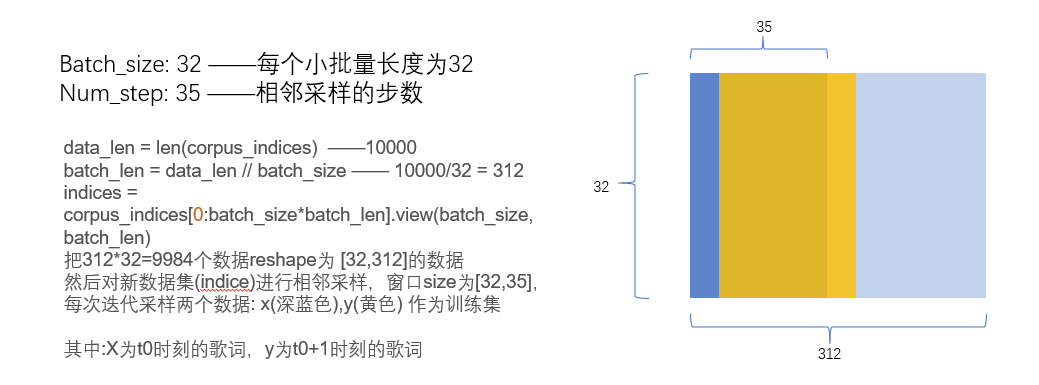
搭建模型
这里我们搭建一个 input_size = 1027, num_hidden = 256, output_size =1027, 一层lstm+一层全连接层的模型
1 | |
损失函数为交叉熵,小批量梯度下降的优化器为Adam,学习率见上,忽略。
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!