神经网络-张量引擎
基础步骤:
一般来说,当前所有机器学习系统都使用张量作为基本数据结构。
定义:张量是矩阵向任意维度的推广
张量这一概念的核心在于,它是一个数据容器。它包含的数据几乎总是数值数据,因此它
是数字的容器。你可能对矩阵很熟悉,它是二维张量。[注意,
张量的维度( dimension)通常叫作轴( axis)]。
用ndim属性查看张量轴的个数。
张量的维度是以 数据维度 为核心构造的。
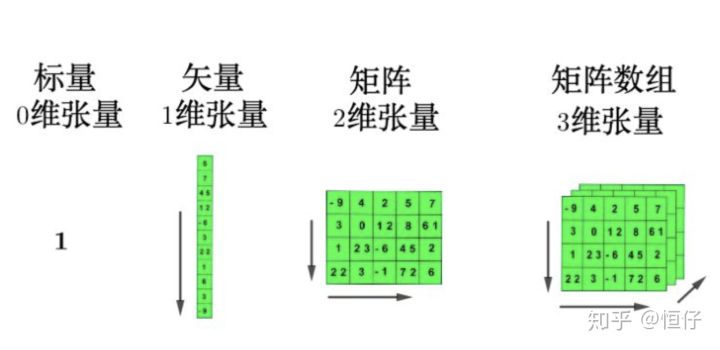
0D张量
又称标量,在 Numpy中,一个 float32 或 float64 的数字就是一个标量张量(或标量数组)。
eg:
array(12); ndim = 0;
1D张量
数字组成的数组叫作向量( vector)或一维张量( 1D 张量)。一维张量只有一个轴。下面是
一个 Numpy 向量
eg:
x = array([12, 3, 6, 14, 7]); x.ndim = 1
是5D向量(5个元素) 1D张量
**
3+D张量
将多个矩阵组合成一个新的数组,可以得到一个 3D 张量,你可以将其直观地理解为数字
组成的立方体。下面是一个 Numpy 的 3D 张量。
eg: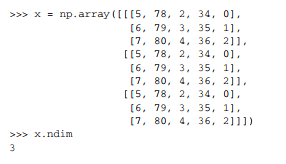
4D类似。
图解张量:
张量运算
1 | |
可以理解为 一个函数 输入input,操作后返回另一个2D张量
我们将上式拆开来看。这里有三个张量运算:输入张量和张量 W 之间的点积运算( dot)、
得到的 2D 张量与向量 b 之间的加法运算( +)、最后的 relu 运算。 relu(x) 是 max(x, 0)。
RELU详解
逐元素运算
该运算独立地应用于张量中的每个元素
方法:
1 | |
广播
在Dense 层中,我们将一个 2D 张量 wx 与一个向量 b相加。如果将两个形状不同的张量相加,会发生
什么?—— 较小的张量会被广播( broadcast),以匹配较大张量的形状。
具体步骤
(1) 向较小的张量添加轴(叫作广播轴),使其 ndim 与较大的张量相同。
(2) 将较小的张量沿着新轴重复,使其形状与较大的张量相同。
eg: maximum运算
1 | |
张量点积
点积运算,也叫张量积( tensor product,不要与逐元素的乘积弄混),是最常见也最有用的
张量运算。与逐元素的运算不同,它将输入张量的元素合并在一起。
对于两个矩阵 x 和 y,当且仅当 x.shape[1] == y.shape[0] 时,你才可以对它们做点积(dot(x, y))。
得到的结果是一个形状为 (x.shape[0], y.shape[1]) 的矩阵,其元素为 x的行与 y 的列之间的点积。
图解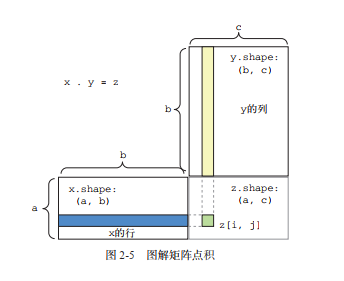
维度:(a,b) . (b,c) → (a,c)
高维拓展
(a, b, c, d) . (d,) -> (a, b, c)
(a, b, c, d) . (d, e) -> (a, b, c, e)
不太清楚操作的意义
张量变形

引擎——基于梯度的优化
随机梯度下降
**
小批量随机梯度下降——SGD
基于当前在随机数据批量上的损失,一点一点地对参数进行调节。由于处理的是一个可微函数,你可以计算出它的梯度,从而有效地实现第四步。沿着梯度的反方向更新权重,损失每次都会变小一点。
- 抽取训练样本 x 和对应目标 y 组成的数据批量。
- 在 x 上运行网络,得到预测值 y_pred。
- 计算网络在这批数据上的损失,用于衡量 y_pred 和 y 之间的距离。
- 计算损失相对于网络参数的梯度[一次反向传播( backward pass)]
- 将参数沿着梯度的反方向移动一点,比如 W -= step * gradient,从而使这批数据
上的损失减小一点。
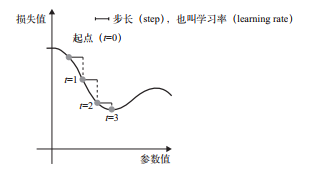
小批量在:一次抽取一批数据,变种可以为 每次抽取一个样本;每次用全部数据
注意点:为 step 因子选取合适的值是很重要的。如果取值太小,则沿着
曲线的下降需要很多次迭代,而且可能会陷入局部极小点。如果取值太大,则更新权重值之后
可能会出现在曲线上完全随机的位置。
基于注意点的变种:
基于 优化器的梯度下降
引入概念: 动量
关注** 收敛速度和局部极小点**
更新参数 w 不仅要考虑当前的梯度值,还要考虑上一次的参数更新
eg:
1 | |
Q:不太理解V的概念,学到优化器再补充
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!