操作系统 内存图像
内存图像
本文资源来自 哈工大李治军老师的 操作系统原理与实践 课程
实验地址:https://www.lanqiao.cn/courses/115
课程地址:https://www.bilibili.com/video/BV1d4411v7u7
部分图文来自 《操作系统真像还原》 郑刚,带我走进操作系统
概述
内存视图可以分为三部分
- 段:偏移模式
- 页模式
- 段页结合,虚拟内存
理解内存视图之前,首先必须理解这张图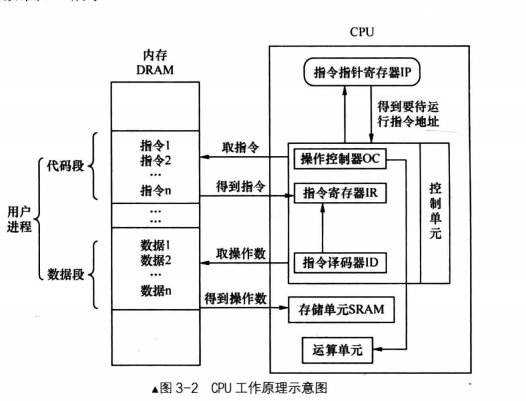
了解** 取址执行 **,其中DRAM和SRAM ROM部分放到计组部分讲解
段:偏移模式
段+偏移是取址执行的关键部分,在实模式使用段地址<<4+偏移取值,在保护模式以后使用段选择子+偏移查多种表来取址。接下来正式介绍。
实模式分段
在8086中,因为16位系统需要用到20位内存(1MB),所以采用了段<<4+偏移的方式,而实模式的*实 *体现在使用的是真实的物理地址,而保护模式为了对用户态透明内存,使用虚拟内存作为遮蔽。这里简单写一下,但不代表他不重要,必须吃透。
实模式寄存器
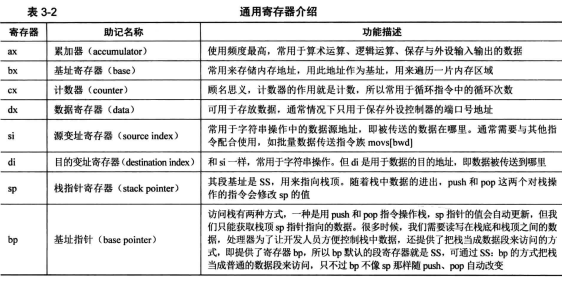
寻址方式,从大方向来看可以分为三大类:
( 1 )寄存器寻址:
(2 )立即数寻址:
(3 )内存寻址,把操作数从内存中读取
在第 种内存寻址中又分为:
( l )直接寻址: mov ax, [0x1234] 读的就是 ds:0x1234的地址
(2 )基址寻址:mov [bp],ax //eg:把sp提前mov给bp,保护sp
(3 )变址寻址:mov [si+0x1234],ax
(4 )基址变址寻址 mov [bx+di],ax
分段目的
8086之前,程序对内存的访问是 写死 的,地址必须写死,即硬编码,这会导致安全性和复杂度问题加重。为了解决,可以先给程序分配指定区域内存(20位),把该内存按照 16位+0000的起始地址(段基址),0000H-ffffH的偏移“数组”取址。
保护模式分段
保护模式32位寄存器拓展
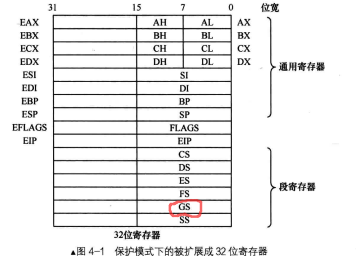
寄存器中低 16 位的部分是为了兼容实模式,可以单独使用。高 16 位没办法单独使用,只能在用 32位寄存器时才有机会用到它们。
PE模式寻址
基址寄存器不再只是 bx bp,而是所有 32 位的通用寄存器,变址寄存器也是一样,不再只是 si di ,而是除 esp 之外的所有 32通用寄存器,偏移量由实模式的 16 位变成了 32 位。并且,还可以对变址寄存器乘以一个比例因子(1,2,4,8)
mov eax,[eax+edx*8+0x12345678]
但是在PE及以后,段+偏移不只是右移4位再相加,而是段选择子+偏移量查表GDT
GDT 全局描述符表
到了保护模式下,内存段(如数据段、代码段等〉不再是简单地用段寄存器加载下段基址就能用啦,段的信息增加了很多,需要提前把段定义好才能使用
段描述符
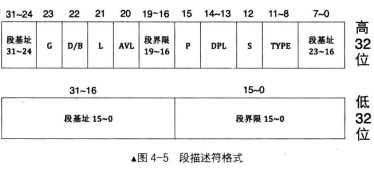
段界限用来限制段内偏移,依靠G(粒度),这里不做介绍。
段寄存器 cs DS ES FS GS SS ,在实模式下时,段中存储的是段基地址,即内存段的起始地址。而在保护模式下时,由于段基址已经存入了段描述符中,所以段寄存器中再存放段基址是没有意义的,在段寄存器中存入的是一个叫作选择子的东西一-selector 。选择子“基本上”是个索引值,确定段描述符&属性
段基址放在描述符表中,cpu通过寄存器的选择子+偏移选择对应描述符表,描述符表经过处理读取内存对应地址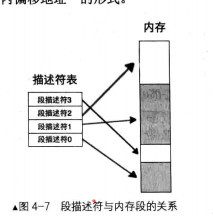

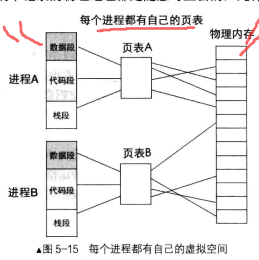
内存分页机制,畅游虚拟空间
为什么要分页
连续进程块再多进程图像中不现实,引入连续进程块是为了介绍 线性地址.我们把段基址+段内偏移地址称为线性地址,线性地址是唯一的,只能属于某1个进程 , 而程序也能用线性地址是连续的
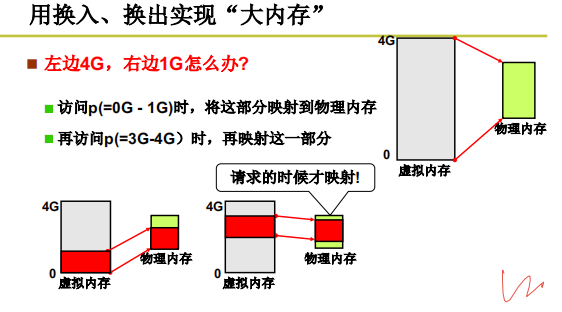
如果使用线性地址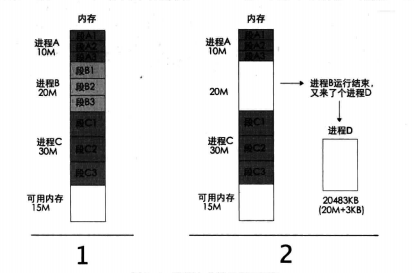
1阶段执行完成,B进程腾出内存,这时候CPU安排进程D进内存, 如果是连续地址,D进程不够用了.因此需要如图4-7一样,将物理内存拆开,不连续的使用.
按照这种思路,我们首先要做的是解除线性地址与物理地址一一对应的关系,然后将它们的关系重新
建立。通过某种映射关系,可以将线性地址映射到任意物理地址,这就是页表的原理
一 二级页表
原理
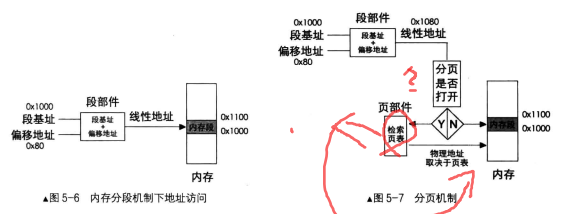
作用
分页机制的作用有两方面
• 将线性地址转换成物理地址。
• 用大小相等的页(一般4KB)代替大小不等的段。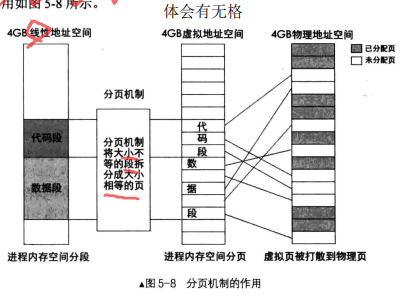
一级页表
页是地址空间的计量单位,并不是专属物理地址或线性地址,只要是 阻的地址空间都可以称为一
页,所以线性地址的一页也要对应物理地址的一页。一页大小为 4KB ,这样一来, 4GB 地址空间被划分
4GB/4KB=lM 个页,也就是 4GB 空间中可以容纳 1048576 个页,页表中自然也要有 1048576 个页表项,
这就是我们要说的一级页表。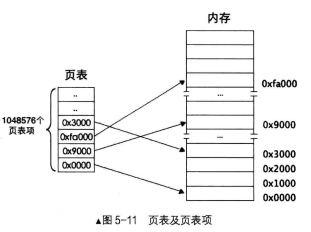
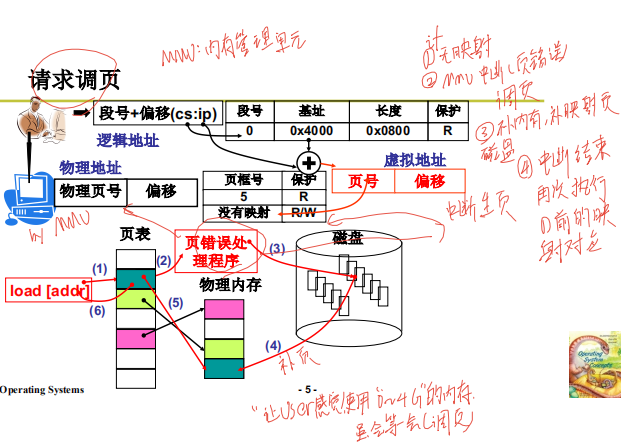
eg: mov ax,[0x1234]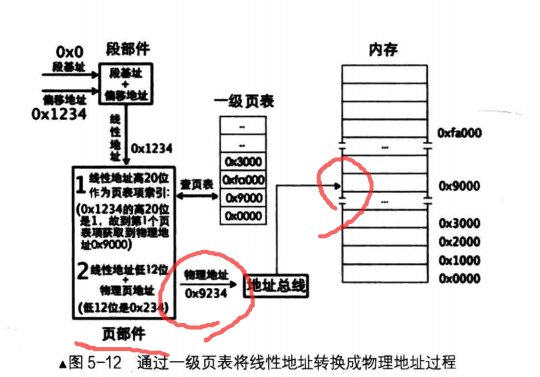

二级页表
用页目录表+页表来处理,总共是4KB10241024,即可以映射4GB的物理内存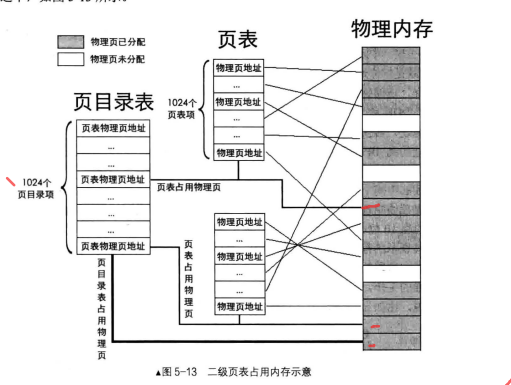

寻址逻辑:
经以上分析,二级页表地址转换原理是将 32 位虚拟地址拆分成高 10 位、中间 1o 位、低 12 位三部分,它们
的作用是:高 10 位作为页表的索引,用于在页目录表中定位 个页目录项 PDE,页目录项中有页表物理地址,
也就是定位到了某个页表。中间 10 位作为物理页的索引,用于在页表内定位到某个页表项 PTE ,页表项中有分
配的物理页地址,也就是定位到了某个物理页。低 12 位作为页内偏移量用于在已经定位到的物理页内寻址。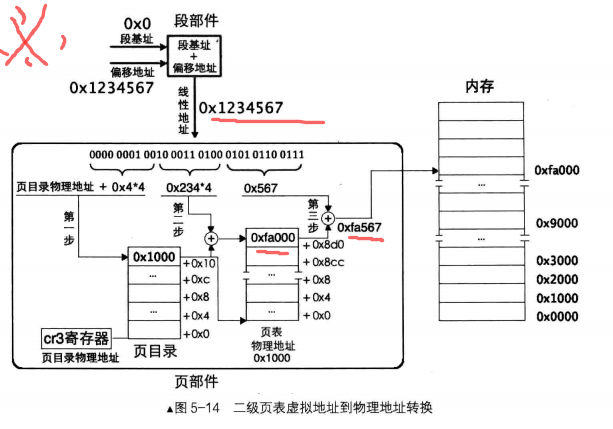
内存换入&换出
换入
换出
换出逻辑跟换入类似,所以主要讲如何选择换出页
思想: 并不能总是获得新的页,内存是有限的 需要选择一页淘汰,换出到磁盘,选择哪一页?
FIFO(先入先出)
即每次缺页的时候就替换掉最开始的那一页,这种算法肯定在这个方面肯定不是最好的算法,因为它没有任何机制保证替换次数尽可能少。
MIN算法
选择最远将使用的页淘汰,什么意思呢?假设这个进程只分配了三个页框,现在分别存储了A、B、C三页,假设进程后面使用的页数依次是:C、B、A、D、C、B、A、B、C,使用C、B、A的时候不用换页,当使用D的时候,先看一下后面最远使用的页是哪个,然后将它换掉;对于上例,最远使用的页是A,于是便将A换出,将D换入。可以看出这种方法是最好的方案,但是它实现不了。因为它需要事先知道进程后续要使用哪些页,而这点是做不到的。
LRU算法
唐太宗李世民在《旧唐书·魏徵传》中说过:“以铜为镜,可以正衣冠;以古为镜,可以知兴替;以人为镜,可以明得失。”;其中“以古为镜,可以知兴替”说的就是可以通过历史来预测未来(当然原句的翻译是:用历史当作镜子,可以知道国家兴亡的原因;)。虽然不能知晓未来,但是可以通过前面调用的页的顺序来推测未来哪些页是常用的。理论基础就是程序的空间局部性。
LRU算法就是这样:选最近最长一段时间没有使用的页淘汰(最近最少使用)。
LRU算法的准确实现:用时间戳
用时间戳来记录每页的访问时间,比如某个进程访问页的顺序为:A 、B 、C 、A 、B 、D 、A 、D 、B 、C 、B;该进程只有三个页框。那么使用时间戳
实现,如下图:
第一次将A放入页框中,并记录当前时间为1;第二次将B放入页框中,并记录当前时间为2;第三次将C放入页框中,并记录当前时间为3;第四次又是访问A页,更新A页访问时间,第五次访问B页,更新B页访问时间;第六次访问D页,不存在,那么就在A、B、C页中选择一个最早使用的也就是数字最小的替换,即C页。这种方式理论上是可行的,但是每次地址访问都要修改时间戳,需要维护一个全局时钟,需要找到最小值……实现代价太大了。
LRU算法的准确时间:用页码栈
还是上面的例子,
每次地址访问都需要修改栈,实现代价也比较大。其实LRU准确实现用的少,因此维护代价太高了。从上面两种算法可以看出,主要是在维护时间戳上面花费的时间比较多,但是能不能将LRU算法做一个优化呢?或者说近似实现?
clock算法
LRU的近似实现 - 将时间计数变为是和否
二次机会算法
具体操作是这样的,每页增加一个引用位( R ),每一次访问该页时,就将该位置为1。当发生缺页时用一个指针查看每一页的引用位,如果是1则将其置为0,如果是0就直接淘汰。如下图:
用这种方式实现就不必维护时间戳了,提高了内存使用效率。但是这种算法真的可以使用吗?在实际中,缺页的情况肯定不会很多;如果缺页很多了,说明内存太小了或者算法不行。那当这个算法缺页很少的情况会怎么样呢?假设初始状态所有的页的引用位都是1,这是很有可能的,因为缺页情况少,进程使用的一直是内存里面存在的页。那么当发生缺页时,指针转一圈之后将所有的页的引用位都置为0,没找到能替换的,继续转,这时候发现最开始那个页引用位为0,将其置换出去,指针后移;然后又一段时间没有发生缺页,所有页的引用位都为1,当发生缺页之后,又会将这一轮最开始的那一页置换出去;然后指针后移,一段时间之后发生缺页,又会将这一轮最开始的那一页置换出去。wait…,这不是变成FIFO了吗。
究其原因还是因为指针扫描的时间太长了,也就是记录了太长的历史信息。其中一个解决办法是再加一个指针用来清除每一页的引用位,可以放在时钟中断里面,定时清除;这个时间可以事先设置好,也可以在软件里面实现。
给进程分配多少个页框
嗯嗯,现在置换策略有了,但是还有一个问题需要解决:给进程分配多少个页框。
如果分配的多了,那么请求调页导致的内存高效利用就没有了。而且内存就那么大,如果每一个进程分配很多的话,跑的进程数量就少了。如果分配的少,系统内进程增多,每个进程的缺页率增大,当缺页率大到一定程度,进程就会总等待调页完成,导致cpu利用率降低。如下图
中间那个急剧下降的状态称为颠簸。一种可以采用的方法是,先给进程分配一定数量的页框,如果增加页框能增加cpu利用率,就慢慢增加,如果导致cpu利用率减少,就降低页框分配。当然实际情况下每个进程对应的页框数量肯定是得动态调整的。
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!